


 Google has effectively made the discipline of site reliability engineering (SRE) a DevOps best practice by publishing two decades’ worth of lessons in keeping alive the most scalable apps on the planet. As more organizations make the shift (or “transformation,” as it were) to becoming IT organizations, the demand for reliability increases substantially for customer-facing services. SRE represents a department-spanning set of practices and technical ninjas who are not just focused on keeping alive the corporation’s most valuable technical assets; they are also tasked with ensuring operations scale as these services grow. Evolving organizations often recognize the need for SRE as part of their maturity path toward incorporating software-defined IT operations (SDITO) as a way to streamline costs by standardizing tool sets and enabling automation.
Google has effectively made the discipline of site reliability engineering (SRE) a DevOps best practice by publishing two decades’ worth of lessons in keeping alive the most scalable apps on the planet. As more organizations make the shift (or “transformation,” as it were) to becoming IT organizations, the demand for reliability increases substantially for customer-facing services. SRE represents a department-spanning set of practices and technical ninjas who are not just focused on keeping alive the corporation’s most valuable technical assets; they are also tasked with ensuring operations scale as these services grow. Evolving organizations often recognize the need for SRE as part of their maturity path toward incorporating software-defined IT operations (SDITO) as a way to streamline costs by standardizing tool sets and enabling automation.
SRE Basics
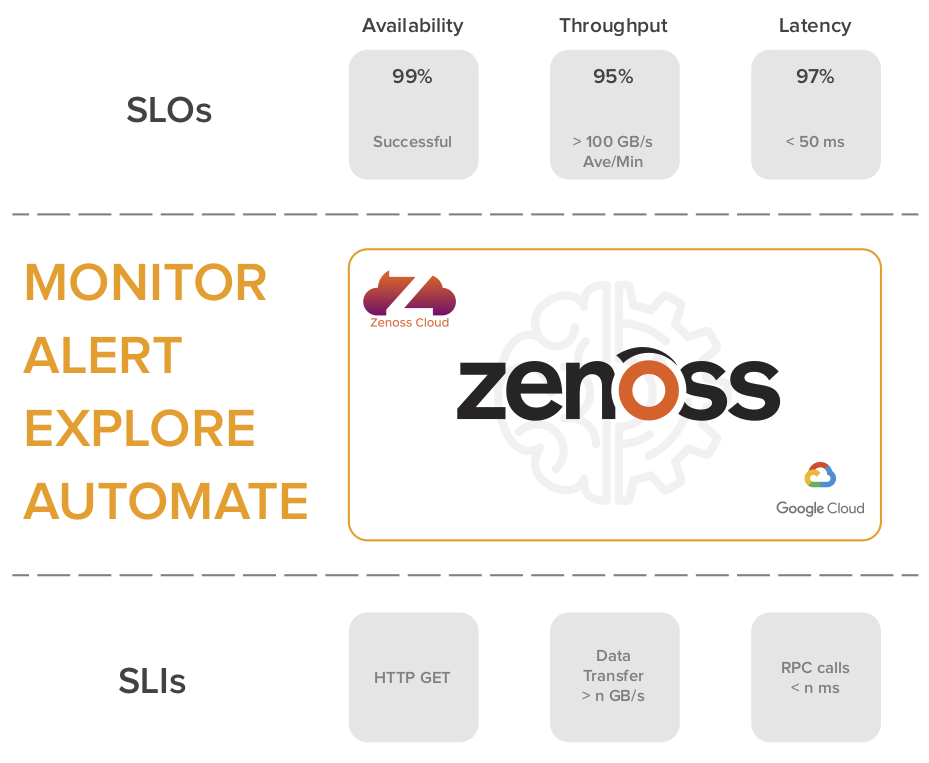
In a nutshell, SRE attempts to rally all groups within an organization around a well-known set of objectives to ensure products/services are reliable (but not overly reliable) in the eyes of the customer. Entrants in the world of SRE often confuse contractually based service-level agreements (SLAs) with the internally driven but often published service-level objectives (SLOs). To clarify, an SLO is based on service-level indicators (SLIs), which are defined by some key measurement of the service. The SLO is determined by how often an SLI remains within a certain range. For example, the SLI might be latency for an API request, and the SLO would represent the amount of time the latency was within the desired range. While some, if not all, SLOs might be published to end users to provide status and set expectations, the contracted SLA would represent what would happen if an SLO was not met (e.g., service credits). Determining the SLOs and SLIs for a service is an evolving process and should be based on what is most important to the end user.
Drinking Our Own Champagne
Zenoss’ journey into a full-fledged SaaS company would not be complete without the need for world-class operations to maintain the health of a service that ensures infrastructure and applications are healthy for others. Like many organizations, Zenoss Cloud has dependencies on hybrid infrastructure, which spans multiple public clouds, as well as infrastructure residing in the customer premises. In setting SLIs and SLOs for Zenoss Cloud, several obvious indicators were apparent, such as availability of collectors, number of queued events per tenant, and the health of Kubernetes (via GKE). All of these indicators and many more are derived from Zenoss Cloud via a second instance — in this case, to avoid the dilemma of the monitor monitoring itself. While vendor and cloud-based tools provide basic information about their respective domains, collecting this information into a single source creates context across disparate infrastructure and provides a common tool for troubleshooting complex problems. As operations of Zenoss Cloud continue to evolve, SLOs will be made more transparent to customers, providing additional confidence for customers using Zenoss Cloud as their SLI/SLO vendor of choice.
For more information on how you can leverage Zenoss Cloud to jump-start your operations practices with SRE, contact Zenoss to set up a demo.






