


On March 23, 11 a.m. CT, I’m sitting down with Naveen Chhabra, infrastructure and operations analyst for Forrester Research, to discuss Dickerson’s hierarchy of service reliability. Naveen has been with Forrester for over seven years, after spending 15 years as a technology leader.
A few years ago, we published a post on Dickerson’s hierarchy of service reliability. This hierarchy comes from Mike Dickerson, a former Google SRE who temporarily joined the radically different culture of the United States government to help with the launch of healthcare.gov in late 2013 and early 2014. With this massive endeavor, they needed a way to explain how to increase systems reliability in complex IT environments. Leveraging Maslow’s hierarchy of needs — a theory of psychological health predicated on fulfilling innate human needs in priority — Dickerson came up with his hierarchy of service reliability.
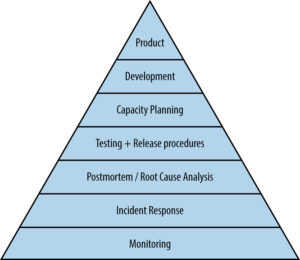
There’s an entire e-book, simply called, “Site Reliability Engineering,” and this is just one section from that e-book. I’ve never met Mike Dickerson, and I doubt he is even aware that we reference him or write about him. But I really appreciate it when technical people apply vision/theories/models from domains outside of technology, and I especially love this one. The gist is that in order to achieve higher order goals, you must first address more foundational needs, and there is an order or priority in which those should be addressed.
The hierarchy isn’t something Naveen created, or even endorses. But he provides strategic guidance to Forrester's clients and offers guidance for technology leaders to develop dependable and reliable technology infrastructures, so this is right in his wheelhouse.
Want to know what you’re getting yourself into by joining the webinar? To give you a sneak peek, here are the questions I plan to ask Naveen:
- What was your first impression when you saw this hierarchy?
- The SRE book says, “We need monitoring systems that allow us to alert for high-level service objectives, but retain the granularity to inspect individual components as needed.” How do you see this being accomplished today in organizations that have more mature strategies in place?
- The SRE book says monitoring tools need to “ensure their reason for existence: to measure the service’s alignment with business goals.” How well do you think organizations are able to do this, i.e., measure an IT service’s alignment with business goals?
- Let’s talk about observability. First, how do you explain to people what observability is?
- Where does observability fit into this hierarchy? Or does it not?
- Incident response is the second tier (from the bottom) in the hierarchy. This is one of the areas where we see customers leveraging robust monitoring to get more value out of their incident response tools. Are you seeing this among your clients? What are typical integrations you see in this area and what benefits are they delivering to customers?
Naveen is an extremely smart guy with unique insights on modern infrastructure strategies and architectures, and I’m excited to get his take on all of this. I hope you can join us for the conversation.






