


 If you are in IT Ops or DevOps, hardly a day goes by without someone mentioning AIOps. There are a few who think AIOps can replace IT Ops tools today. Others debate this, saying that AIOps is still a nascent field, and it will take a few more years until we see a full-fledged AIOps platform for IT operations management. But there’s always been a lot of confusion on how AIOps really works.
If you are in IT Ops or DevOps, hardly a day goes by without someone mentioning AIOps. There are a few who think AIOps can replace IT Ops tools today. Others debate this, saying that AIOps is still a nascent field, and it will take a few more years until we see a full-fledged AIOps platform for IT operations management. But there’s always been a lot of confusion on how AIOps really works.
Deconstructing Different Layers of AIOps and Its Capabilities
AIOps stands for artificial intelligence for IT operations. At a high level, AIOps tools do two things: they collect data and they analyze data. They do this in the interest of accelerating problem resolution in IT operations. But reducing AIOps to just these two broad areas completely ignores many of the foundational elements of true AIOps solutions — especially ones that really seek to successfully leverage AI in order to streamline IT operations. We’ve identified nine distinct capabilities — with a bottom-up approach — starting with data collection, then moving up through the layers to self-learning capabilities. 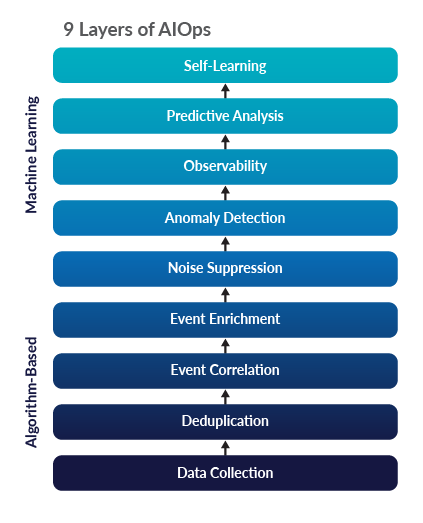
Data Collection – This is the key foundational component that fuels complex machine learning algorithms to analyze and see patterns that IT Ops teams, in general, wouldn’t find. If you are a large organization managing thousands of devices and millions of nodes globally, it is highly unlikely that you could manually sift through all available complex machine data in your environment, including metrics, events, streaming data, traces and log data, and predict upcoming application or system failure within any given time. A flexible, comprehensive data collection mechanism is what any AIOps tool needs. But IT Ops teams are realizing that their existing tools have limited capabilities and that they need an expansive breadth of data to create meaningful machine learning models. Contrary to what many stand-alone AIOps vendors claim, adding intelligence on top of logs or events alone is not sufficient to create trustworthy automation. For robust self-healing, these tools must be able to stream all data types from different sources to provide enough context to be trustworthy. For instance, Zenoss provides a deep data collection mechanism that enables IT Ops to collect streaming data in real time and gain insights on how to optimize and improve IT performance.
Deduplication - Automatic deduplication is the next critical step when you are processing millions of oncoming events from different data sources at a large scale. For many admins managing hybrid IT environments with some combination of on-premises and public/private cloud infrastructure, reducing event noise automatically saves a lot of time and improves mean time to resolution (MTTR).
Event Correlation and Enrichment - Most monitoring solutions handle event storms by reducing and correlating events across different data sources using statistical analysis. Some stand-alone AIOps solutions approach event correlation with pattern-recognition machine learning (ML) algorithms, but without training the ML algorithms using large sets of contextual data, they fall short of adding much value to users who tend to look for anomalies or insights from the IT environment. For the person or team responsible for the event source, the impact on the business and the initial steps for triage are critical bits of information generally lacking from alerts. You can leverage model-based data and context-aware relationships from your IT infrastructure and use that to suppress and enrich events through AIOps.
Noise Suppression - IT Ops teams always look for actionable alerts that enable them to become more efficient. But one common hurdle is excessive alert noise and fatigue, which can be a hurdle for IT admins who usually seek faster resolution time. Some AIOps solutions deliver intelligent event suppression, enabling admins to selectively discard and reduce event noise — making it easier for them to scale device monitoring and zero in on important problems. It works if you are in large application environments where you have a lot of noisy event sources.
Anomaly Detection - This layer of AIOps is where the technical complexity goes up a notch. For instance, if you are deploying code across your environment, you would want to know the potential service impact. By having advanced machine learning algorithms, you can save development costs by automating the manual process of sifting through the logs and metrics to find out if there are any anomalies or regressions. Observability - One of the key challenges for stand-alone AIOps solutions is the lack of a tremendous amount of raw machine data to train their machine learning algorithms for better observability. For instance, the analysis of one or two types of data (such as metrics, events, logs, tracing, etc.) won’t provide you with necessary insights to debug a hybrid cloud application. You need machine data from all sources/types to fully realize the service context, and machine learning can help you make sense of the mix of high-cardinality data. When you start with a robust and contextual data collection mechanism from different sources as your foundation stone, it enables observability and helps you to act on critical insights that allow you to analyze root cause and speed up troubleshooting and the resolution process.
Predictive Analysis - Given the dynamic nature of IT, where relationships between services and IT infrastructure are constantly changing, proactively preventing impacts to critical business services is never easy. The most useful machine learning insights are informed by real-time infrastructure modeling data as well as large datasets from all other sources. You can stay ahead of the curve by uncovering model-informed trends and patterns that help you optimize your IT resources and plan capacity more effectively.
Self-Learning - Many AIOps vendors are on a path to accelerate machine learning effectiveness with real-time, dynamic models of end-to-end IT services and applications. With supervised or unsupervised training of ML algorithms, including deep learning, AIOps solutions can effectively forecast system or performance failures even before they happen. With AIOps, we could just be scratching the surface right now. One potential upside of expanding AI capabilities beyond these nine layers as AI/ML algorithms become more advanced is that it might even push the limits of AIOps tools to self-heal whenever there is an issue in IT infrastructure. But, for now, we are just in the early stages of adopting and using AIOps capabilities for IT operations management. As a leader in intelligent application and service monitoring, Zenoss can provide machine learning insights informed by real-time model data, as well as all other data types. This creates an unprecedented capability to visualize incidents, forecast trends and detect issues before the business is impacted. For more information on how you can utilize Zenoss Cloud to unify your observability practices across legacy and modern IT environments, contact Zenoss to set up a demo. Additionally, Forrester recently released a report on the two paths to deploying AIOps in your environment. To learn more, download the report here.






