


 Winston Churchill once said, “Out of intense complexities, intense simplicities emerge.” In the IT operations management (ITOM) environment, simplicity actually drives complexity in many ways due to the increasing rate of scale that simplicity affords. In other words, collapsing stacks and converging hardware allows more virtual (i.e. software-defined) entities to arise, and this exponential expansion leads to mind-boggling situations requiring machines to become simplicity brokers.
Winston Churchill once said, “Out of intense complexities, intense simplicities emerge.” In the IT operations management (ITOM) environment, simplicity actually drives complexity in many ways due to the increasing rate of scale that simplicity affords. In other words, collapsing stacks and converging hardware allows more virtual (i.e. software-defined) entities to arise, and this exponential expansion leads to mind-boggling situations requiring machines to become simplicity brokers.
Models, Models Everywhere…
One way to unscramble this tangled and ever-changing entity collection is to create digital representations of the ecosystem (i.e., models), which provide the foundation for simplification to emerge. The entire IT ecosystem is vast, and segmented models are often created based on the area of management focus. In IT operations, two fundamental models are the application model as well as the infrastructure model, and together these models cover the majority of the IT stack for a key business function. Ideally, these models would be combined to provide maximum insights — however, a single source of model truth is hard to find in the ITOM marketplace. The following diagram shows a static breakdown of how these two models combine/overlap to form a simplified, digital view of an intensely complicated stack.
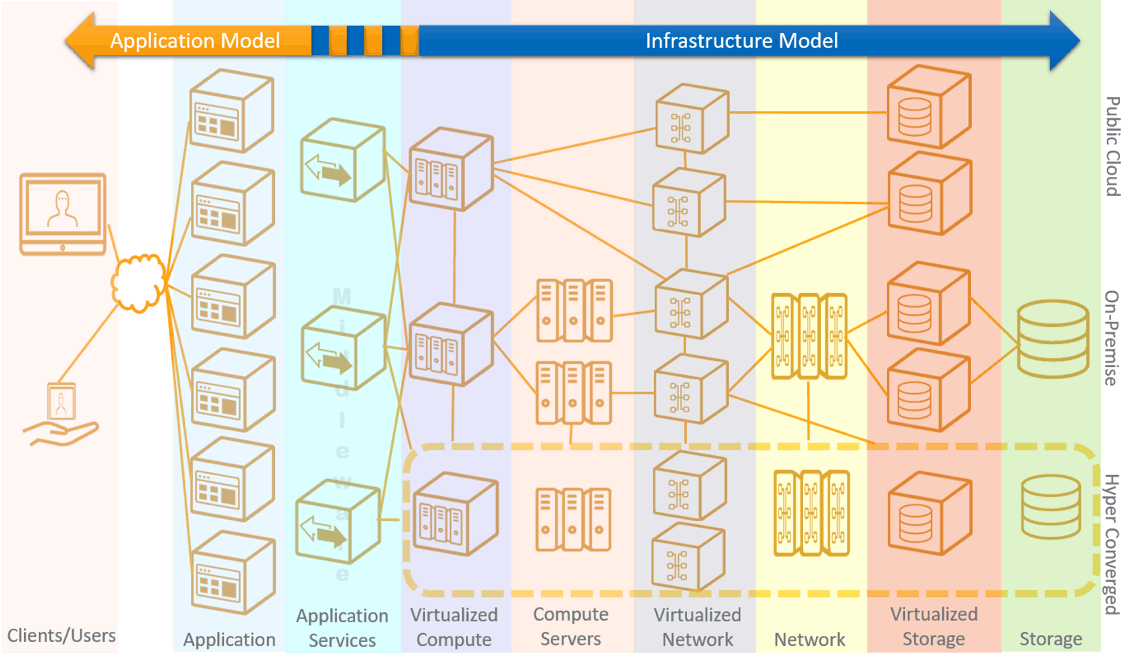
Why Going Deeper is Better
Admittedly, application and infrastructure models are both inherently complicated in both similar and unique ways. On the application side, millions of endpoints must be mapped to virtual entities within the application layers. And on the infrastructure side, these application entities must be mapped into an interlaced mashup of infrastructure made up of on-premises, hyperconverged and cloud-based services (i.e., hybrid). These layers of the stack comprising the interrelationships of the compute, network and storage are often referred to as “deep infrastructure,” and as discussed in previous posts (here and here), the IT infrastructure model is derived from this deep infrastructure. Predictive problem detection and root cause for existing issues are severely hampered without knowledge of this deep infrastructure, and in many cases, this lack of insight significantly increases mean time to resolution (MTTR) for essential business services. Said differently, with this simplified view of the deep infrastructure, IT operations teams are able to stop problems before they affect the end user and track down problems sooner when problems do arise.
Modern ITOM tools such as Zenoss provide deep inspection of the entire IT infrastructure across all platforms and give operators understanding of the environment not afforded by simply viewing application health or relying solely on logs. To learn more, hear from industry experts and other IT operations teams tackling similar problems at GalaxZ18.






