


 Network service providers are beginning to make a big change. They are beginning to use virtualization to replace fixed-function network devices. A typical provider will be installing racks of OpenStack servers in dozens or hundreds of locations. Once complete, they will be able to cut the time to create and roll out new products from several years to several weeks.
Network service providers are beginning to make a big change. They are beginning to use virtualization to replace fixed-function network devices. A typical provider will be installing racks of OpenStack servers in dozens or hundreds of locations. Once complete, they will be able to cut the time to create and roll out new products from several years to several weeks.
These huge projects raise some very challenging questions. Fundamentally, how do you keep tens of thousands of service chains, running on thousands of servers in hundreds of locations, healthy? The organizations in pilot now have almost uniformly decided to replace their current monitoring processes.
In this three-part series, were going to look at how Zenoss supports network function virtualization (NFV) monitoring for infrastructure, identifies service chain fault/root cause, and integrates service chain functional monitoring.
This is part one, network function virtualization infrastructure — commonly known, of course, as NFVI.
NFV Infrastructure Monitoring Use Cases
Zenoss is working with our partner Cisco in a dozen service providers in project stages from pilot to early production. We’re finding common needs across every customer:
- Pod-level awareness — it’s critical to know the relationships between server hardware, OpenStack, Ceph storage and network devices
- Single-source monitoring for everything in a pod
- Provider-level scale with central monitoring for all the pods
- Fully automated monitoring updates in response to provider CRUD activity
- Usage by current and projected use by pod, not by individual components
Providers built existing network services by trucking a stack of dedicated function network equipment to each location and connecting it according to a common plan. Many providers included a monitoring appliance in each stack, with a central user interface that could connect to any location as needed.
As providers dig into NFV, they are finding big issues with those appliances. Let’s dig into these one at a time, exploring each need and identifying common shortcomings in existing processes.
Pod-Level Awareness
With NFV, providers are deploying one or more pods at each location. A pod is the server hardware, Ceph storage, and physical switches supporting a single OpenStack farm. When you have large numbers of pods, you want to understand issues affecting pods, not devices. The key need is to understand that the Fresno office has a problem, not that server #3891 is overheating. When you know the pod, you know who is affected and how to attack the problem.
Single-Source Monitoring
The only way to maintain pod-level awareness is to collect detailed data from every component of the pod with one system. That means logical components like virtual machines and VLANs, too. If you can’t deeply understand every component, you can’t understand and identify how faults in one piece of infrastructure are affecting others, and problem source identification takes too long.
Provider Scale
When we talk about scale, there are two concerns. The first is obvious: Can our solution handle the raw volume of data we’re going to throw at it? The second is just as critical: Can we operate the solution efficiently?
One of the biggest issues with the monitoring appliance model was the difficulty in protecting against risk. How do you provide for backup, and does someone need to be present for recovery? What if the appliance breaks entirely — what are the steps to recover? How do we roll out a critical security patch? The complexity of the NFV environment makes these problems harder to solve, and appliance models fall short.
The ideal solution needs to run as a virtual appliance with fully automatic recovery upon faults. You don’t want to store any data locally, because then you don’t need local backup and recovery processes. You want central configuration, because otherwise you’d need to repeat it for every location.
Automated CRUD Updates
Although providers may start out with similar server configurations for each pod, different usage at each location will quickly change that. One of the great advantages of the NFV infrastructure is that it’s very easy to expand capacity by adding more servers, especially with Cisco’s VIM doing the automation. When new servers are added (or removed!), the monitoring setup needs to change at the same time so that providers can immediately use the new capacity. Monitoring configuration shouldn’t be a bottleneck.
Usage by Pod
Each pod uses multiple shared servers to provide compute resources for service chains, network interfaces for VLANs, and shared storage capacity. Evaluating resource usage means building a combined view across multiple devices with a similar role. If you want to know whether there’s enough capacity to add another service chain, you need an overall view across all the compute resources.
Integration With Cisco VIM
To address these use cases, Zenoss worked with Cisco to build the Cisco VIM ZenPack. Let’s look at the integration.
Cisco VIM automates provisioning, management and upgrading of an OpenStack environment. It enables providers to build NFV infrastructure pods with Cisco UCS servers, Nexus switches and RedHat OpenStack.
The Zenoss VIM ZenPack integrates with the Cisco VIM software to fully provision monitoring in Zenoss. With the ZenPack installed, you can deploy and add/remove physical and logical resources to each pod without ever needing to reconfigure the monitoring system.
Once you’ve installed the ZenPack and authenticated to the Cisco VIM software, Zenoss automatically tracks pod resources — logical networks, switches, compute, storage and management nodes — as you can see from the VIM device screen shot below.
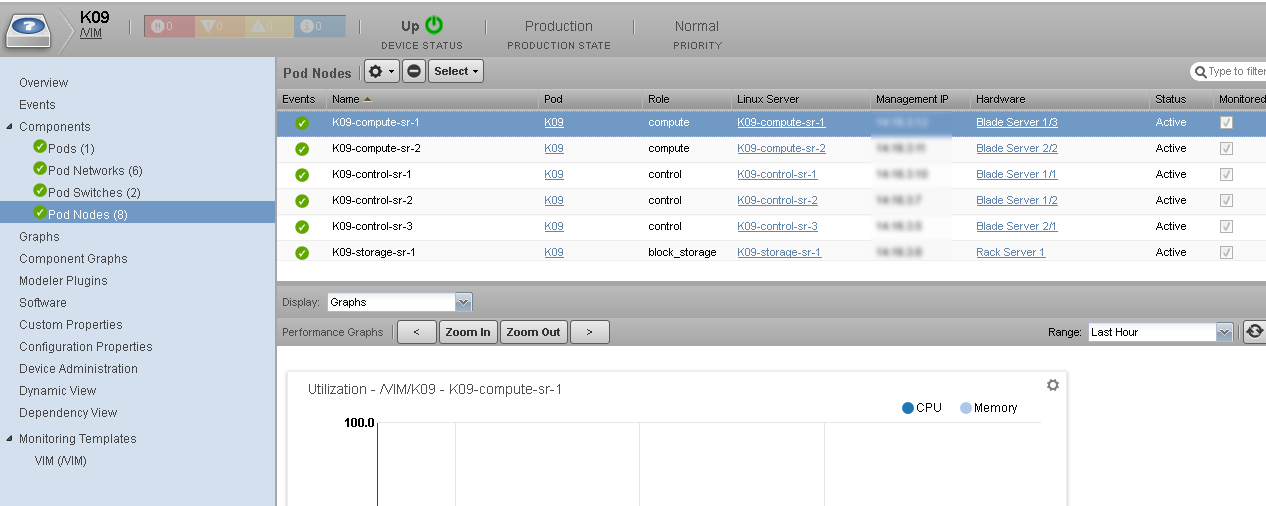
After the individual pod devices are added, Zenoss uses its standard unified monitoring coverage of OpenStack, Docker, Linux, Cisco UCS, Ceph and Nexus to provide single-source monitoring.
Wait, Docker? Yes, because Cisco VIM deploys OpenStack management services in a highly available configuration using Docker containers. There are identical OpenStack services running inside containers in three NFVI control servers in each pod.
In addition to creating a VIM device for each pod, the integration also automatically creates systems organizers to provide pod-level awareness. It’s easy to review the list of all the pods, navigate directly to the pod reporting an issue, then identify which compute, control, hardware network or storage component is at fault.
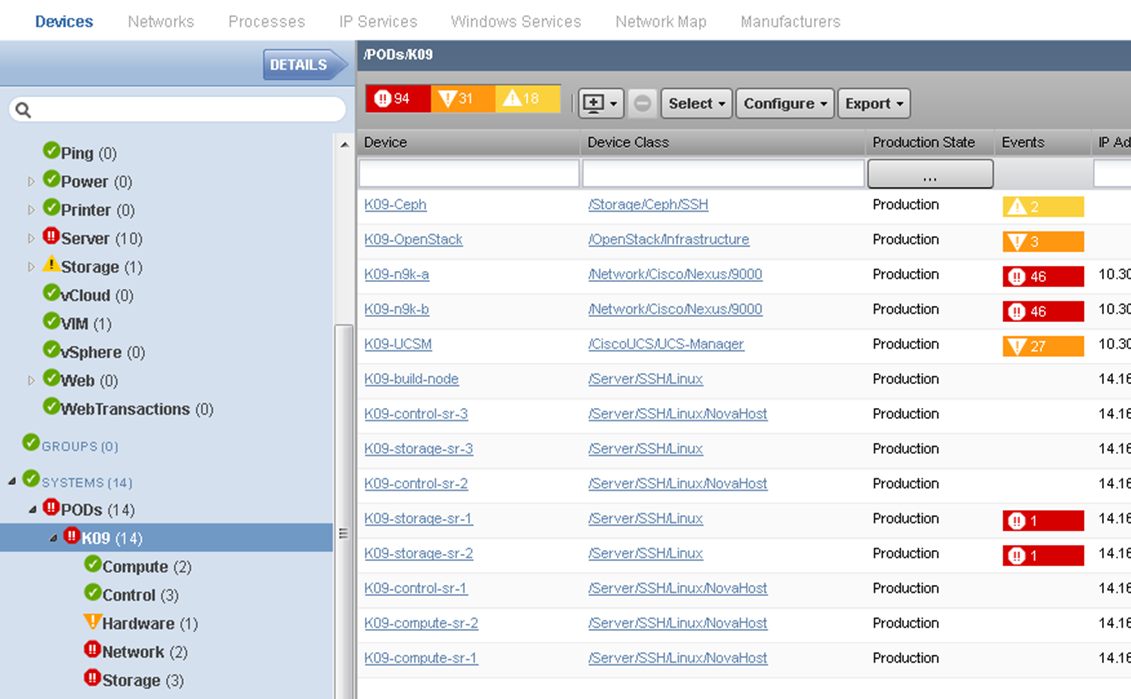
We’re doing more than monitoring individual devices for performance metrics. Monitoring templates for pods use the Calculated Performance ZenPack to create aggregated metrics across similar pod resources. That means we can identify the total capacity used across all the compute nodes, track maximum utilization for each private network, watch total storage utilization, and predict when any pod will run out of resources if usage keeps growing at its current rate.
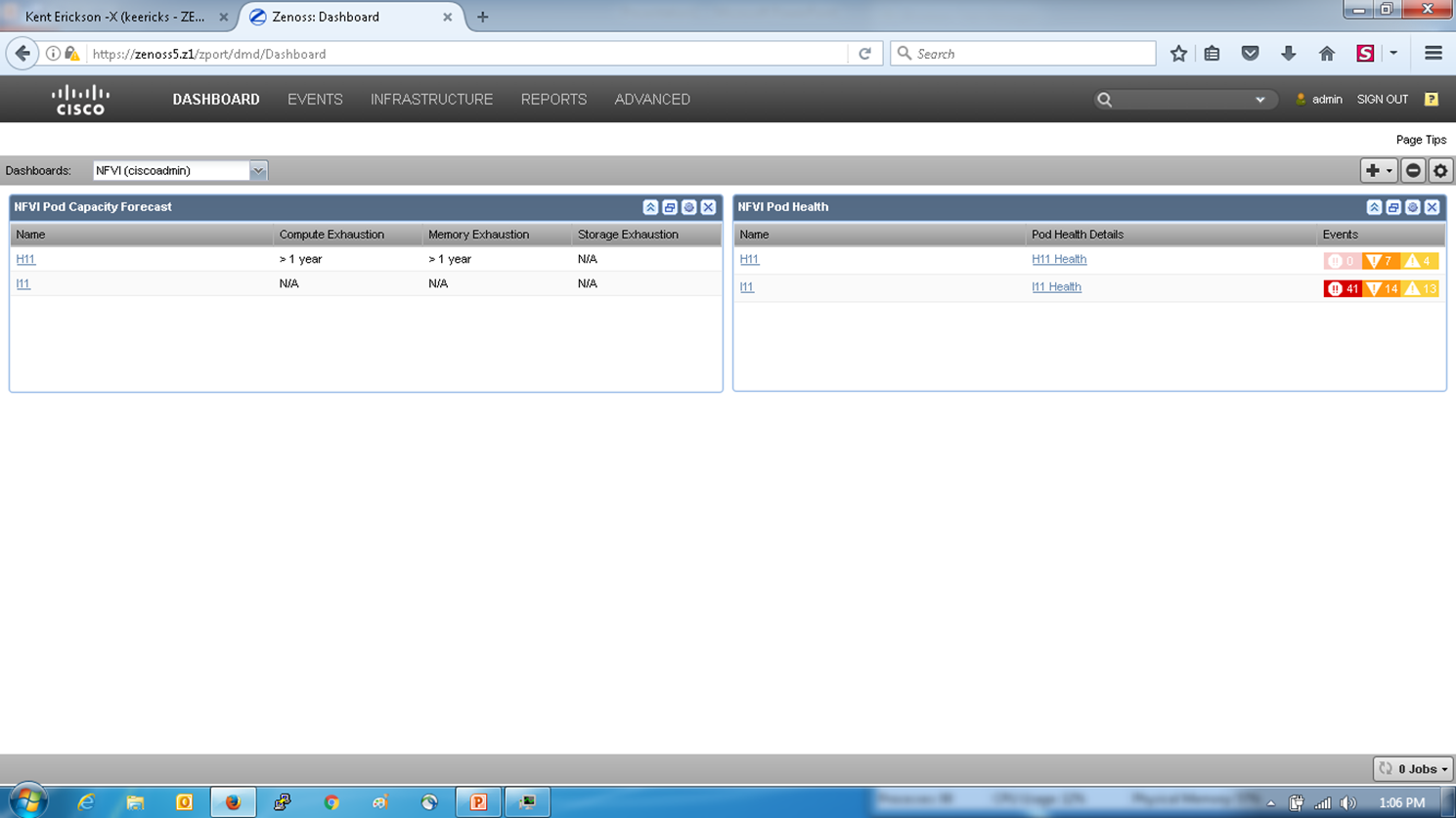
A couple of new dashboard portlets provide quick access to summary views of this information. In particular, the NFVI Pod Capacity Forecast makes it simple to spot which pods are in danger of running out of resources due to growing utilization.
With dozens of pods to monitor, we’ve taken advantage of the new Zenoss service-oriented platform to place a collector pool in each pod. A collector pool integrates with the pod VIM, builds and tracks changes to the pod model, and collects all the fault, performance and availability data. We’ve built our pool using two virtual machines, so that either can fail without monitoring being interrupted. Collector pools send all the data to a central Resource Manager pool, don’t store any data locally, and are completely deployed and configured by the central Control Center pool. This means there’s no need to perform any type of per-pod, on-premises services like backup, recovery, patching or version updates.
What Next?
Our next article will look at how Cisco Network Services Orchestrator and Zenoss work together to provide full infrastructure awareness for every service chain.
NFV has been an exciting challenge for Zenoss, and one we’re thrilled to work on. We’d love to address your gnarliest infrastructure monitoring problems, too. Talk to one of our experts and learn how Zenoss can help you!






