



With acronyms being espoused faster than they can be interpreted, every IT operations pro has their favorite MTT-fill-in-the-blank. Often, these mean-time-to-whatevers are brushed off with a grin and a simple, “Sure, that makes sense.” For most of us, the idea behind many of these MTT-somethings is they provide a medium to discuss some sort of optimization, usually in the context of availability of a critical business function.
Even though early versions of mean time between failure (MTBF) were used to indicate machine reliability, numerous industries have spawned their own measurements to help indicate areas of optimization. Accordingly, the IT operations space has its own variations, and the image below attempts to depict the most commonly used mean times for vital business services with brief explanations below.
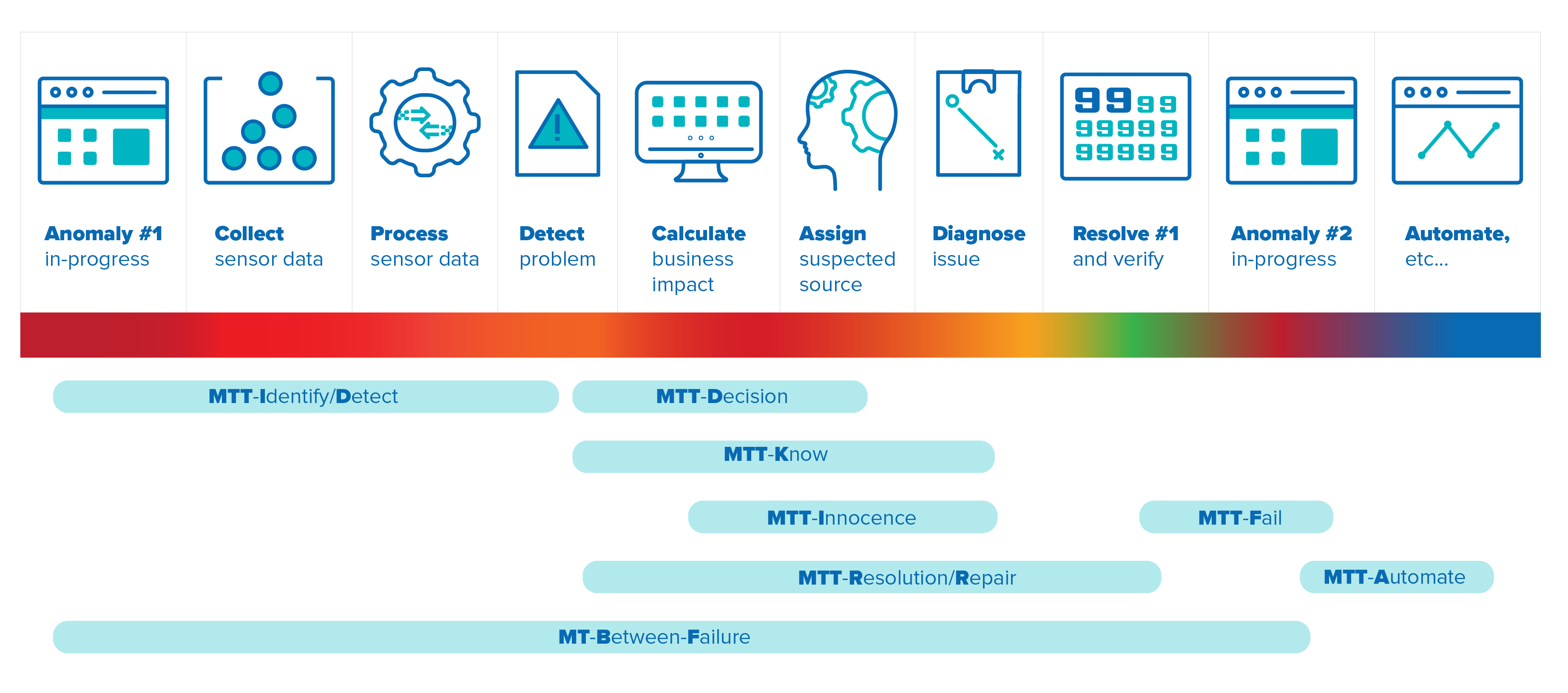
- MTTI/MTTD - Mean Time to Identify (or Mean Time to Detect)
Elapsed time to signal that a problem has occurred in the environment - MTTD - Mean Time to Decision
Elapsed time before a decision is made to address a detected issue - MTTK - Mean Time to Know
Elapsed time before the root cause of the problem is determined - MTTI - Mean Time to Innocence
Elapsed time for independent IT groups to claim the business outage is not in their area - MTTF - Mean Time to Fail
Elapsed time from the resolution of one problem until the next problem occurs - MTTR - Mean Time to Resolution (or Mean Time to Repair)
Elapsed time to fix the problem once it has been detected
NOTE: An alternative is to start measuring once the business impact has been determined, since the problem may be deemed noncritical and solved at a later time. - MTTA - Mean Time to Automate
Elapsed time to repair previous issue(s) using automation to collapse various phases - MTBF - Mean Time Between Failure
Classical elapsed time from one problem until the subsequent problem
Undoubtedly, there is some debate as to the boundaries for some of these, but hopefully, it serves as a starting point for conducting productive conversations around availability and uptime. While different IT operations management (ITOM) products focus on improving different aspects, the ultimate payback is eliminating outages. As software-defined IT operations attempts to inject machine learning and artificial intelligence into the IT ecosystem, the focus on automation will lead to zero perceptible failures by the end user. In other words, the self-healing nature of the data center will provide an always-on reality for users of the key business systems.
If you’re interested in learning how advanced IT shops are leveraging the latest ITIM platforms to reduce MTT-anything, consider joining me at GalaxZ18.






